




















Recent approaches have shown promises distilling diffusion models into efficient one-step generators. Among them, Distribution Matching Distillation (DMD) produces one-step generators that match their teacher in distribution, without enforcing a one-to-one correspondence with the sampling trajectories of their teachers. However, to ensure stable training, DMD requires an additional regression loss computed using a large set of noise-image pairs generated by the teacher with many steps of a deterministic sampler. This is costly for large-scale text-to-image synthesis and limits the student's quality, tying it too closely to the teacher's original sampling paths. We introduce DMD2, a set of techniques that lift this limitation and improve DMD training. First, we eliminate the regression loss and the need for expensive dataset construction. We show that the resulting instability is due to the fake critic not estimating the distribution of generated samples accurately and propose a two time-scale update rule as a remedy. Second, we integrate a GAN loss into the distillation procedure, discriminating between generated samples and real images. This lets us train the student model on real data, mitigating the imperfect real score estimation from the teacher model, and enhancing quality. Lastly, we modify the training procedure to enable multi-step sampling. We identify and address the training-inference input mismatch problem in this setting, by simulating inference-time generator samples during training time. Taken together, our improvements set new benchmarks in one-step image generation, with FID scores of 1.28 on ImageNet-64x64 and 8.35 on zero-shot COCO 2014, surpassing the original teacher despite a 500X reduction in inference cost. Further, we show our approach can generate megapixel images by distilling SDXL, demonstrating exceptional visual quality among few-step methods.
Our method distills a costly diffusion model (gray, right) into a one- or multi-step generator (red, left). Our training alternates between 2 steps: 1. optimizing the generator using the gradient of an implicit distribution matching objective (red arrow) and a GAN loss (green), and 2. training a score function (blue) to model the distribution of “fake” samples produced by the generator, as well as a GAN discriminator (green) to discriminate between fake samples and real images. The student generator can be a one-step or a multi-step model, as shown here, with an intermediate step input.
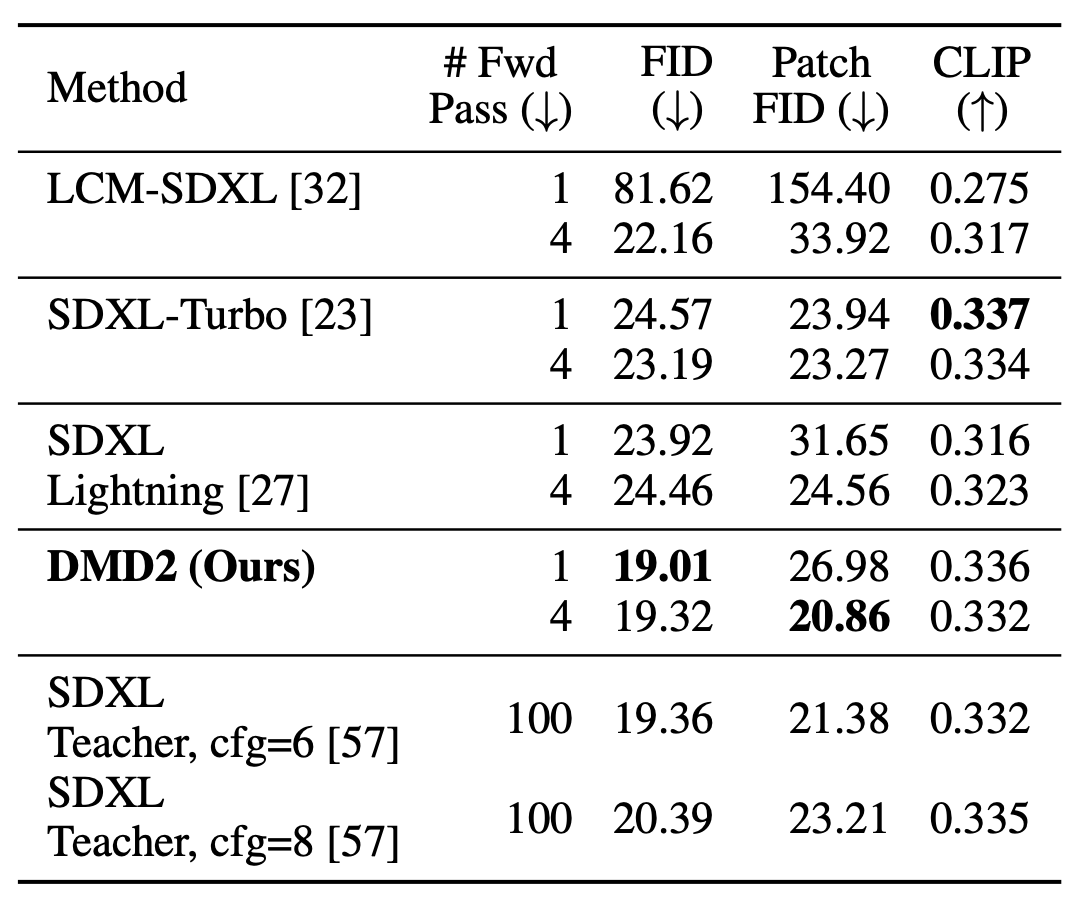
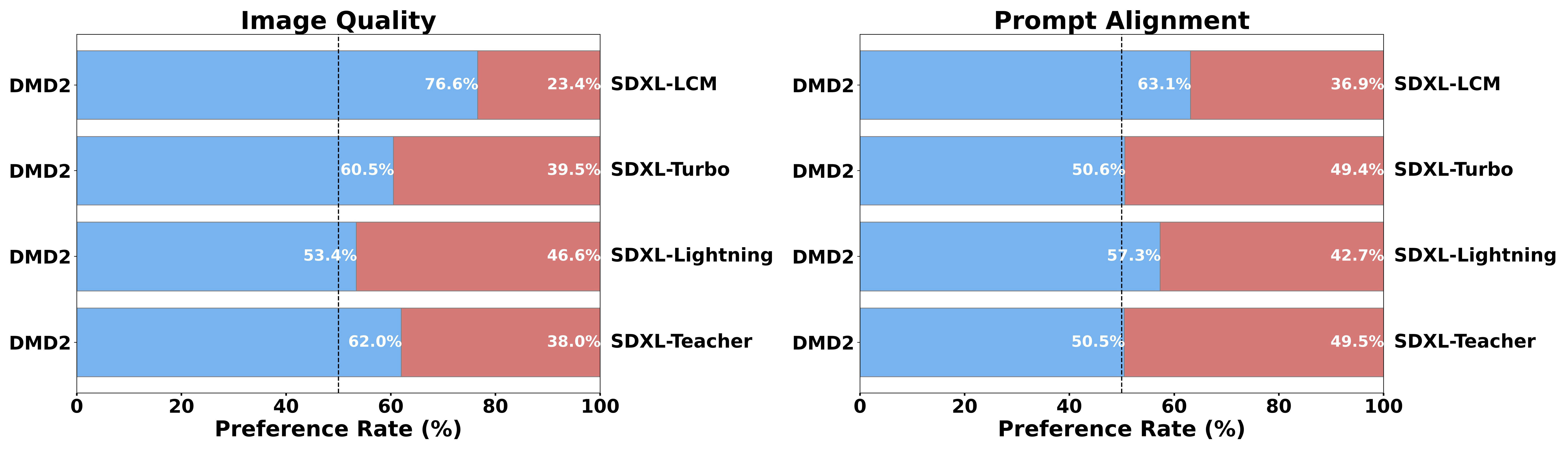
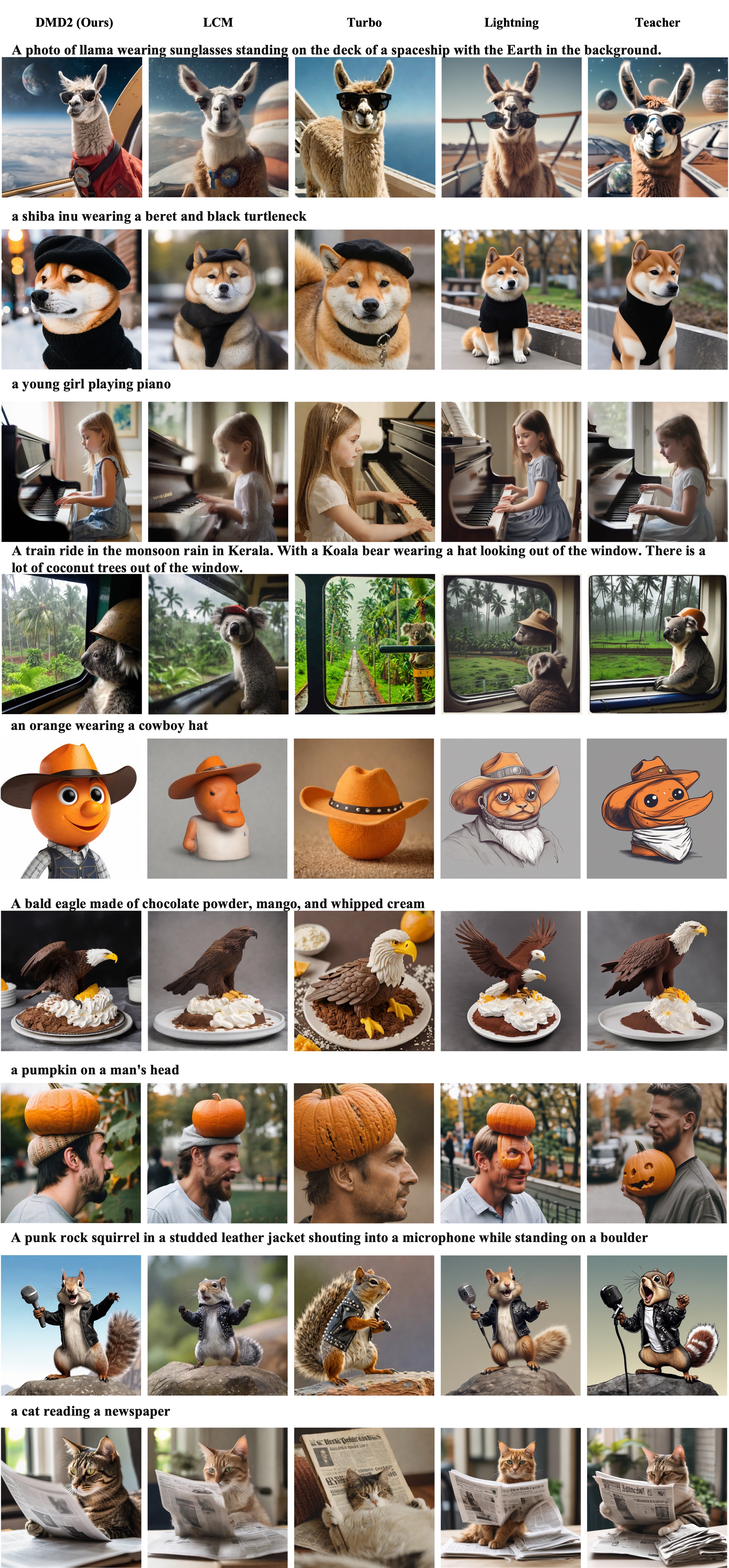
We conduct a human evaluation comparing our distilled model with its teacher and competing distillation baselines. All distilled models use 4 sampling steps, the teacher uses 50. Our model achieves the best performance for both image quality and prompt alignment.
We extend our gratitude to Minguk Kang and Seungwook Kim for their assistance in setting up the human evaluation. We also thank Zeqiang Lai for suggesting the timestep shift technique used in our one-step generator. Additionally, we are grateful to our friends and colleagues for their insightful discussions and valuable comments. This work was supported by the National Science Foundation under Cooperative Agreement PHY-2019786 (The NSF AI Institute for Artificial Intelligence and Fundamental Interactions, http://iaifi.org/), by NSF Grant 2105819, by NSF CISE award 1955864, and by funding from Google, GIST, Amazon, and Quanta Computer.
@inproceedings{yin2024improved,
title={Improved Distribution Matching Distillation for Fast Image Synthesis},
author={Yin, Tianwei and Gharbi, Micha{\"e}l and Park, Taesung and Zhang, Richard and Shechtman, Eli and Durand, Fredo and Freeman, William T},
booktitle={NeurIPS},
year={2024}
}