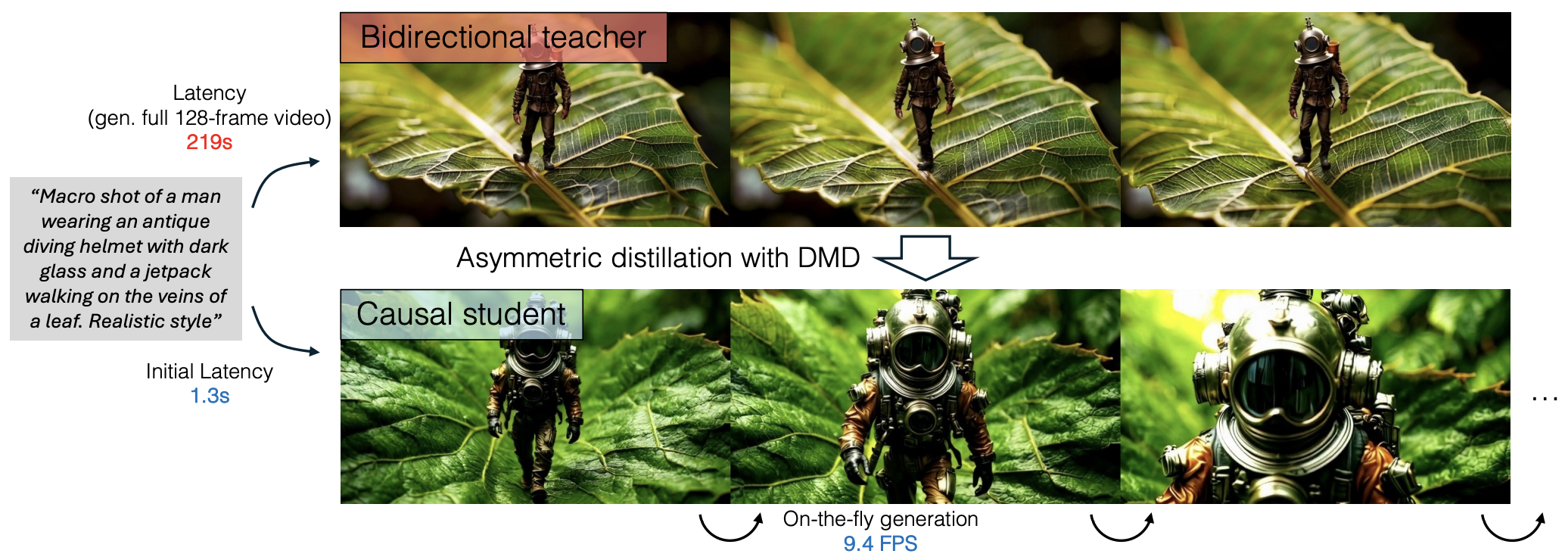
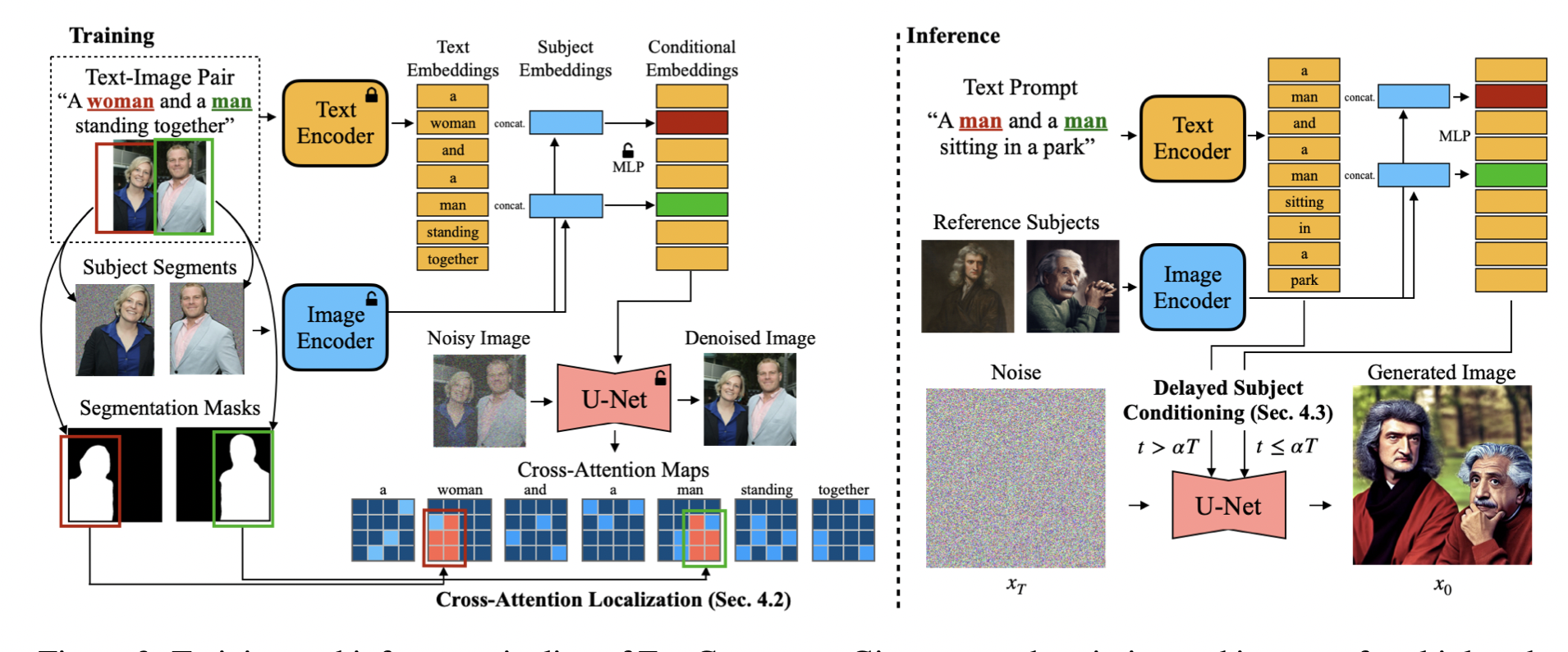
Tianwei Yin
I'm a research scientist at Reve.
I received my Ph.D. in Electrical Engineering and Computer Science from MIT, where I was advised by Frédo Durand
and Bill Freeman.
During my Ph.D., I had the opportunity to collaborate with the incredible team at Adobe, led by
Eli Shechtman.
Before that, I graduated with the highest honor from UT Austin in 2022, where I was fortunate to work with
Philipp Krähenbühl,
Katie Bouman,
and Yisong Yue.
My current research centers on large-scale generative models (diffusion, LLM) for content creation.
tianwei.yin@reve.art